Appearance
PID的局限性
- PID增益调参难
- 系统摩擦、阻尼的改变会让参数需要重新调整(鲁棒性差)
- 忽略了信息和模型
事实上,PID的调参过程就内含对系统进行动力学建模。
以推箱子为例子,PID只会考虑与期望位置的偏差,更为理想的控制应该要估算箱子的重量以及箱子与地面之间的摩擦,从而进行更具有鲁棒性的控制。
一个转动惯量为
在控制中,“积分器串联型”系统是很好用的系统。所谓积分器串联型系统如下:
因此我们自然希望将系统改造成一个积分器串联型的系统。
ADRC
系统建模
要解决PID的鲁棒性差的问题,我们首先想到的是对系统方程中的转动惯量
假设估计值都使用
其中
设
如果令输入
代入系统方程,如果
对于这样的二阶积分系统,使用简单的PD控制器, 如
设状态量
则状态模型写为
扩张状态观测器(ESO)
整个ADRC的思路如下
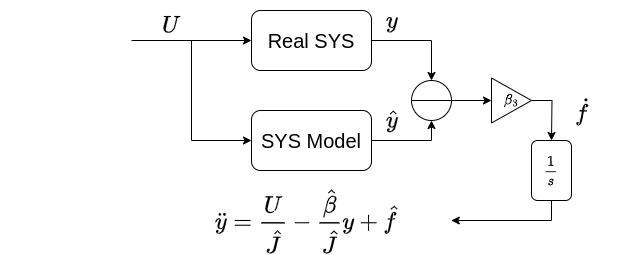
简单来说,就是通过对期望的输出与真实输出的差进行积分实现对SYS Model中总扰动
这里我们建立一个扩张状态模型,其中总扰动
基于此我们要构建一个扩张状态观测器。我们是从总扰动
基于此观测器,我们的控制律设计以及最终闭环动态方程如下
动力学模型:
控制律:
将控制律代入动力学模型,得到闭环系统的动态方程:
实际值与目标值之间的传递函数为:
可见,实际值与目标值的比在稳态时为1,动态过程的响应速度及超调量与
控制律的调节规律为
设
至此,我们就只需要选择合适的
ADRC极点配置
ESO的状态转移矩阵的特征方程如下:
化简得
我们通常希望ESO无超调且快速响应,因此不妨令三个极点相同(设为
令
所以,我们只需要确认观测器的极点